
Data: a swift-foundation deep-dive
Understand the optimisations powering this fundamental struct


Data is both ubiquitous and mysterious.
It’s a block of binary. A bunch of bytes. Big deal?
Data is the WD-40 that lubricates the gears of our applications. The colourless mana that converts network packets to domain objects, files to visible UIImages, or a WebSocket stream into live-chat.
Big deal.
For legacy reasons, Data lives outside the Swift standard library, in Foundation.
Foundation and swift-foundation
The Foundation library is ancient by technological standards, with roots all the way back to the NeXTSTEP operating system that underpins macOS today. It provides basic functionality for all apps, such as data management, text processing, date and time tools, and networking.
In 2022, swift.org announced an open-source, pure-Swift re-write of Foundation in The Future of Foundation. This was motivated by a push towards multi-platform Swift, untethered from Darwin. Swift developers can leverage familiar Foundation functionality while writing systems for the cloud, embedded devices, Windows, and maybe even Android!
The swift-foundation source code is already used in production on Apple platforms, as part of the ubiquitous Foundation umbrella framework. It lives alongside legacy, non-rewritten, C and Objective-C code.
Today, we’re going to look under the hood of swift-foundation and understand exactly how Data is implemented.
Subscribe to Jacob’s Tech Tavern for free to get ludicrously in-depth articles on iOS, Swift, tech, & indie projects in your inbox every week.
Paid members unlock several extra benefits:
Read Elite Hacks, my exclusive advanced content 🌟
Read my free articles 3 weeks before anyone else 🚀
Access my brand-new Swift Concurrency course 🧵.
How Foundation is implemented
First, let’s jump straight to Data.
Right at the top, we see the secret sauce of a cross-platform rewrite:
Lower-level shared system libraries.
A multiplatform swift-foundation is achieved by aliasing C functions common among most computing platforms, such as malloc() and free().

While the implementations are, as you can see, different for different platforms, the core API for libc, the C standard library, is universal. This is the beauty of a ubiquitous language like C forming the backbone of virtually all computing: systems have a common API for implementing common behaviours like allocating memory on the heap, freeing said memory, and comparing bytes.
This is a common theme across swift-foundation and, for that matter, many cross-platform libraries. Platform-specific implementations import the same standard library APIs.
syscalls and malloc
Let’s take a closer look at just one of these functions, on just one platform, to get a deeper picture of what’s going on under each platform implementation.
On Darwin-based Apple systems, the malloc() C function eventually leads down to a syscall into the Mach microkernel, part of the XNU kernel which underpins all Apple platforms. Here’s a partial list of these syscalls in libkernel.
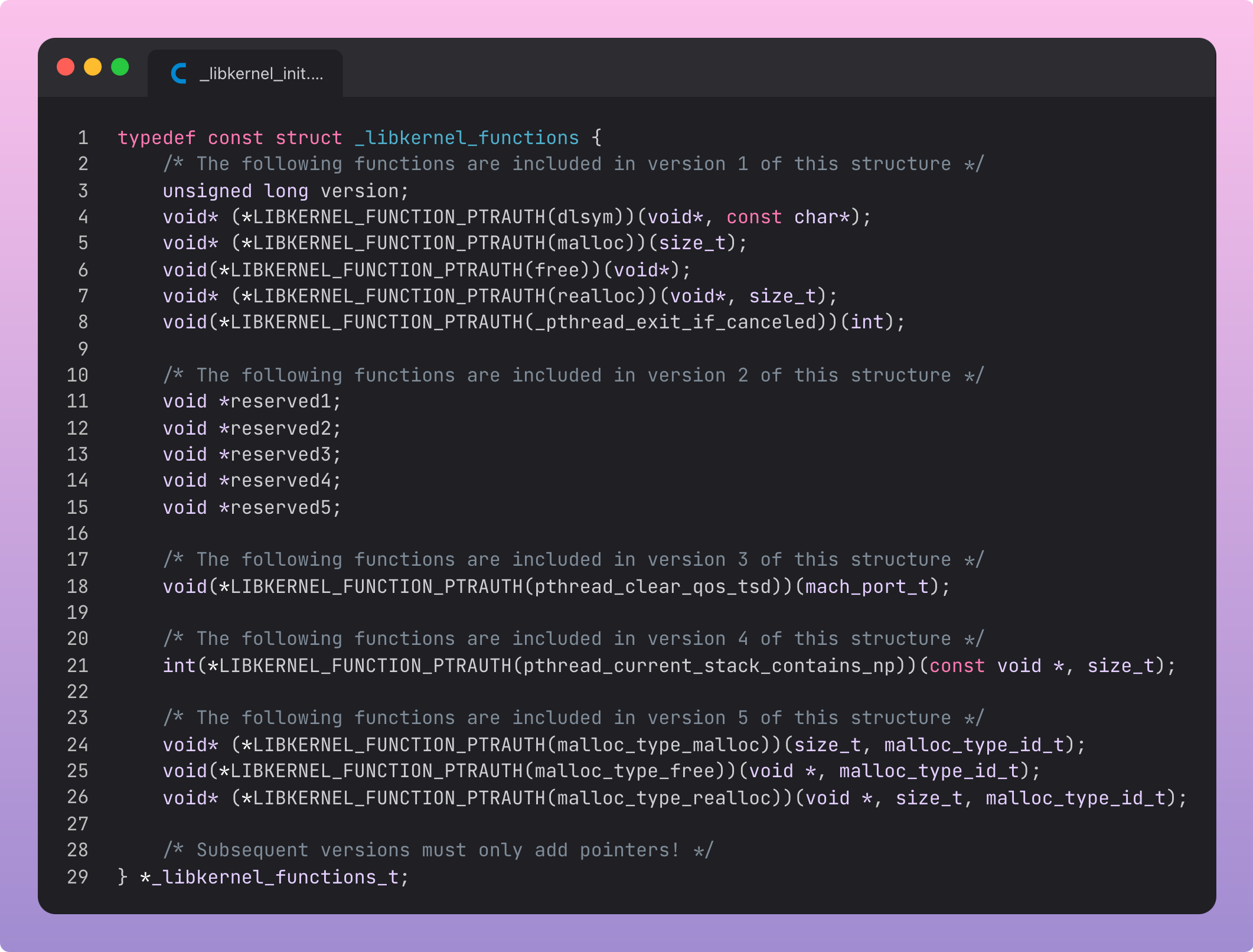
The syscall underneath malloc() invokes the virtual memory subsystem to allocate a block of memory on the heap and return a pointer.
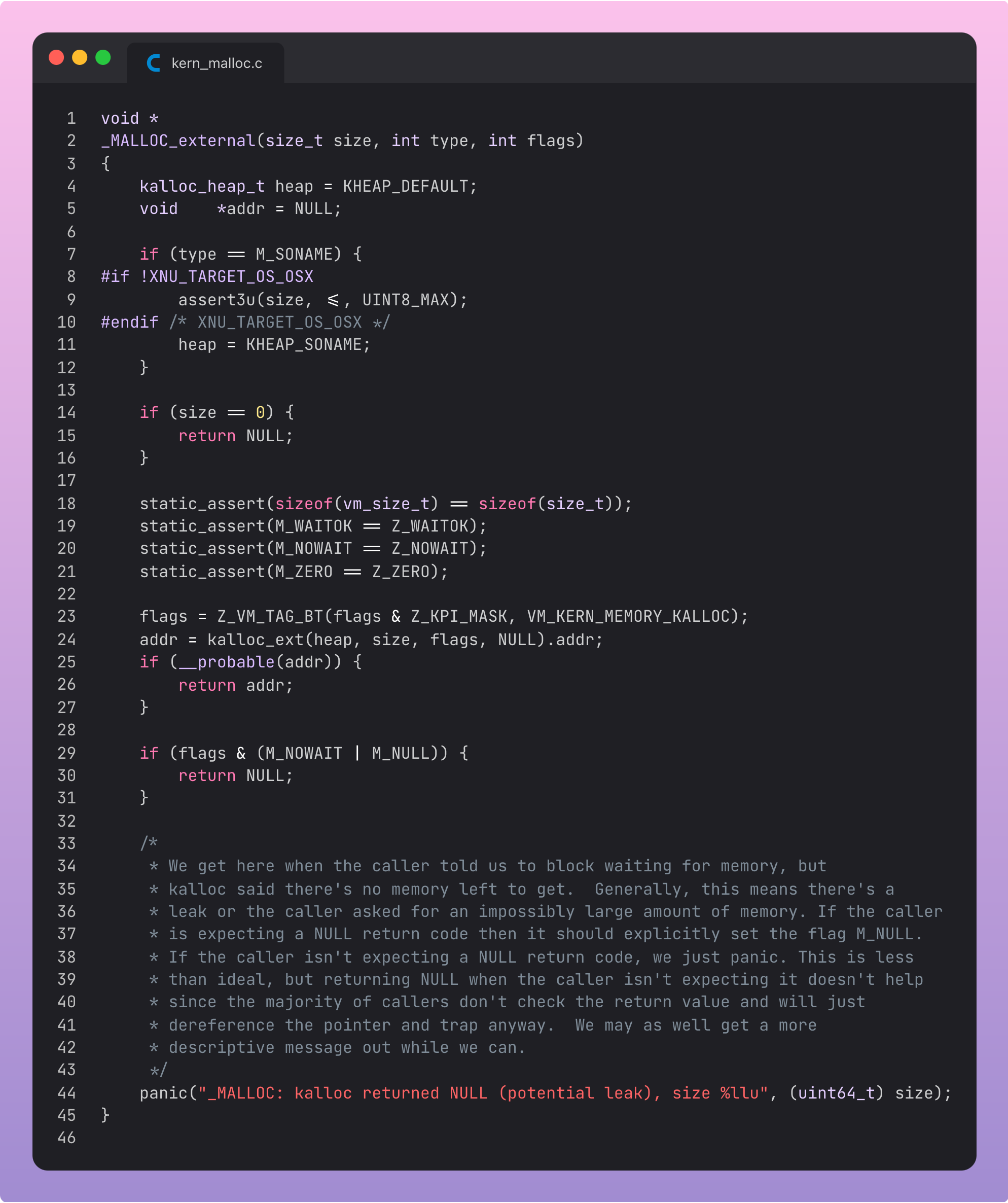
With this single very deep example, we’ve illustrated that basic system-level functionality is implemented for each operating system, with a common API that can be used across all of Foundation.
Therefore, common functionality across the C standard library serves as Foundation’s, uh, foundation.
Now let’s get back to Data.
Data
We can find Data in swift-foundation/Sources/FoundationEssentials/Data/Data.swift.
Data is a lightweight Swift struct with two main jobs:
Manage a pointer to a memory buffer on the heap
Implement various optimisations for performance
Seriously, pretty much everything it does is one of these two things.
There’s beauty in this simplicity.
This simplicity means that even if you’re new to spelunking into open-source system frameworks, it can be relatively understandable.
The Declaration
600 lines of code in, and we land at the actual struct declaration.
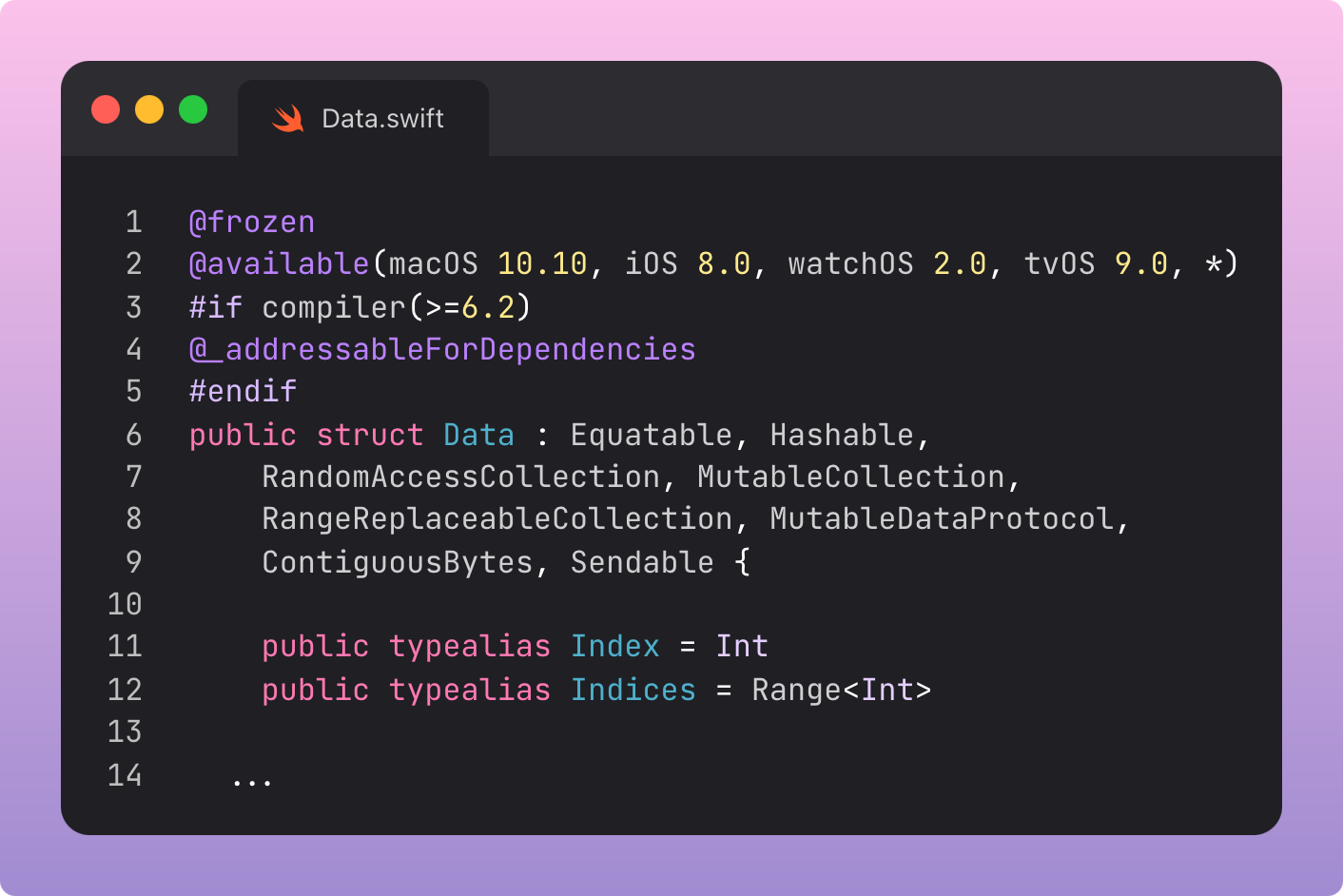
That’s a lot of conformances:
Equatable, Hashable, RandomAccessCollection, MutableCollection, and Sendable are pretty commonplace library protocols.
RangeReplaceableCollection, which supports replacement of any sub-range of its elements with new elements.
MutableDataProtocol, which inherits from DataProtocol. This provides access to an underlying buffer of (lowercase D) data.
ContiguousBytes ensures the type offers access to the underlying raw byte buffer. “Contiguous” means the bytes all lie in a single unbroken block, with all the bits touching.
A pointer to the heap
This is really the main function of Data (big D). Pointing at some data (small d).
Perhaps confusingly, the data doesn’t actually live in Data. It’s all on the heap, referenced by a pointer.
This is actually one of the most basic, ubiquitous optimisations across all of computing.
Instead of working with an enormous 500MB block, which takes milliseconds and many cache pages to even read from RAM, we can use an address pointer that fits in a single CPU register.
This underlying storage of Data’s data is contained within the private __DataStorage type.
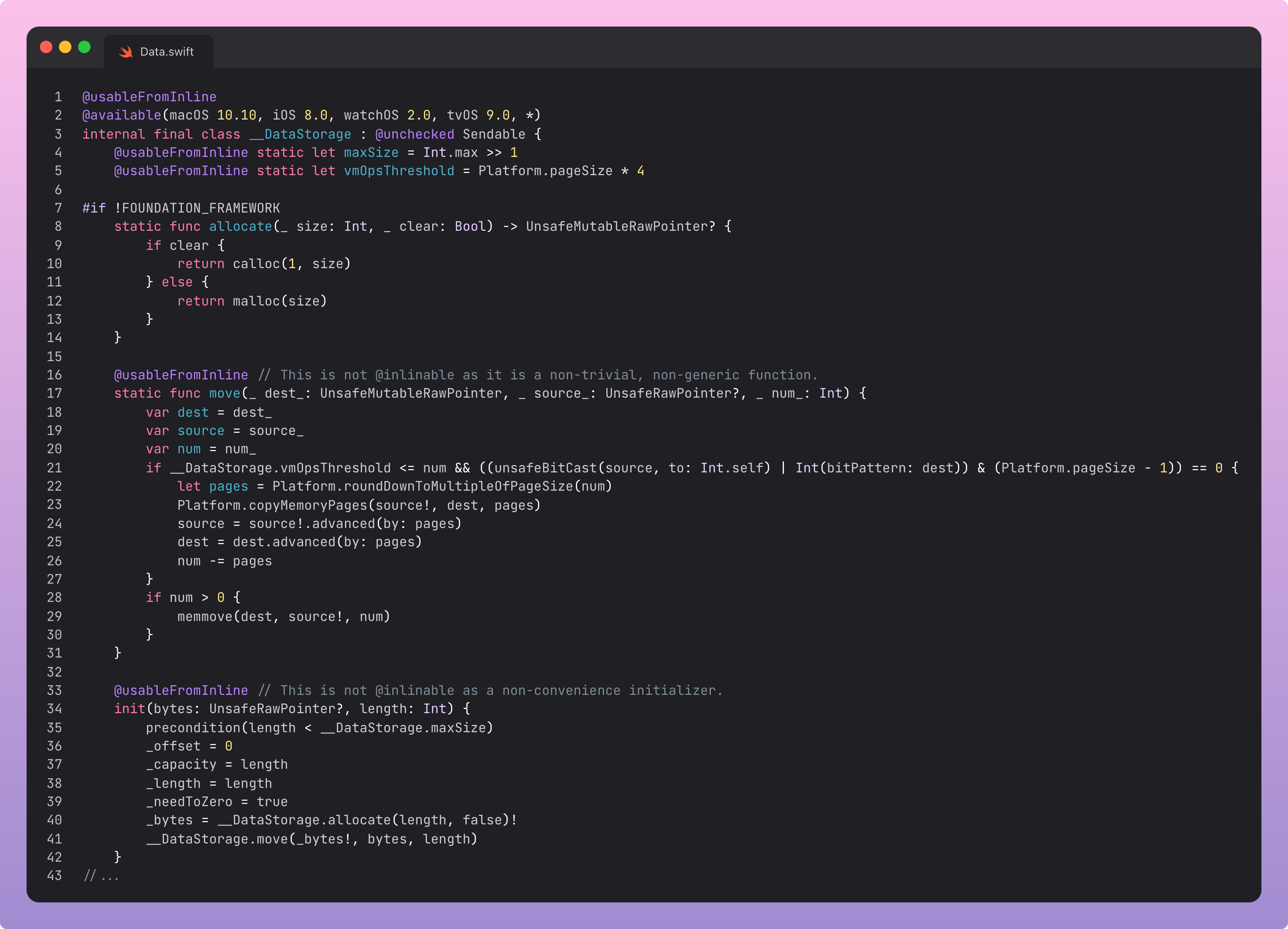
__DataStorage inits using an UnsafeRawPointer, a simple C pointer, to the bytes it will be storing. It sets the relevant metadata such as offset, capacity, length, and of course the bytes.
It allocates this memory on the heap using malloc() and returns a pointer to the new memory. It copies the original data to the memory address of this pointer using memmove() C library function.
The offset property here is handy for efficiency, because it allows a slice of the data (remember it’s a RangeReplaceableCollection!) to act as a window into a larger block of data.
__DataStorage also contains a deallocator that frees the memory in the buffer. Normally this is the C free() method, but some blocks may need platform-specific custom cleanup, for example Darwin’s vm_deallocate that cleans up virtual memory.
__DataStorage also contains my old friend and writing companion, isKnownUniquelyReferenced, as it implements the copy-on-write optimisation. Any underlying storage is shared between any references unless it gets mutated.
So now we’ve seen where Data actually stores memory on the heap. In __DataStorage. What are the rest of the 3022-odd lines of code?
Optimisations, my friend.
Data Optimisations
The core idea with optimisations is avoiding the heap where possible. Storing data on the heap incurs overhead from malloc() and free() calls, as well as far higher likelihood of performance hits from CPU cache misses.
Remember the golden rule: Heap slow, stack fast.
For very small data, we can allocate bytes directly inline on the stack. For larger buffers, we store the underlying data on the heap but can use the stack to work with the data more efficiently.
Consider data representing a single UTF-8-encoded character, a 1-bit flag, or the JSON for { “200” } from a successful HTTP network call. Storing these inline on the stack avoids the substantial overhead of calling malloc() and free(), and improves cache locality. All in all, we use less compute resources, faster, because we’re doing less stuff.
There are a few storage representations used for optimised Data. These apply a different storage strategy based on the size of the data it’s storing.

The most important thing to understand about these representations is that they are all at or below 16 bytes. This is because of how enums with associated values are implemented in Swift.
If an associated value’s memory layout is two “words” or less (2 register words, so that’s 16 bytes on 64-bit platforms), it gets to live inline on the stack. If it exceeds this, then the value is “boxed” into the heap and accessed via a reference. This extra layer of indirection hurts performance, and therefore should be avoided at all cost for such a fundamental library entity like Data.
When initialising the data _Representation, Data checks the unsafe pointer to the underlying data, and assesses its size. It selects the most efficient representation which can fit the data, and moves the bytes over to their new home.
Now, let’s look at these optimised representations in turn.
Empty
This is pretty simple to optimise because there isn’t any data in the Empty representation. Honestly there isn’t much to say here, you get this representation when initialising Data() on its own.
InlineData
This is a small stack-allocated buffer of bytes used for very small data, which can fit inside a couple of register words. The literal bytes are contained within, represented by a tuple of UInt8 values*. The length of this typealiased “Buffer” tuple depends on the CPU architecture of your device (but in 2025 it will almost certainly be the 64-bit version, and store 14 bytes).
*In low-level computing terms, a byte and an unsigned 8-bit integer (
UInt8) are interchangeable. They both look something like10110111, or perhaps0xb7if you’re posh.To make the rest of this article read easier, I will assume 64-bit architecture from now on.
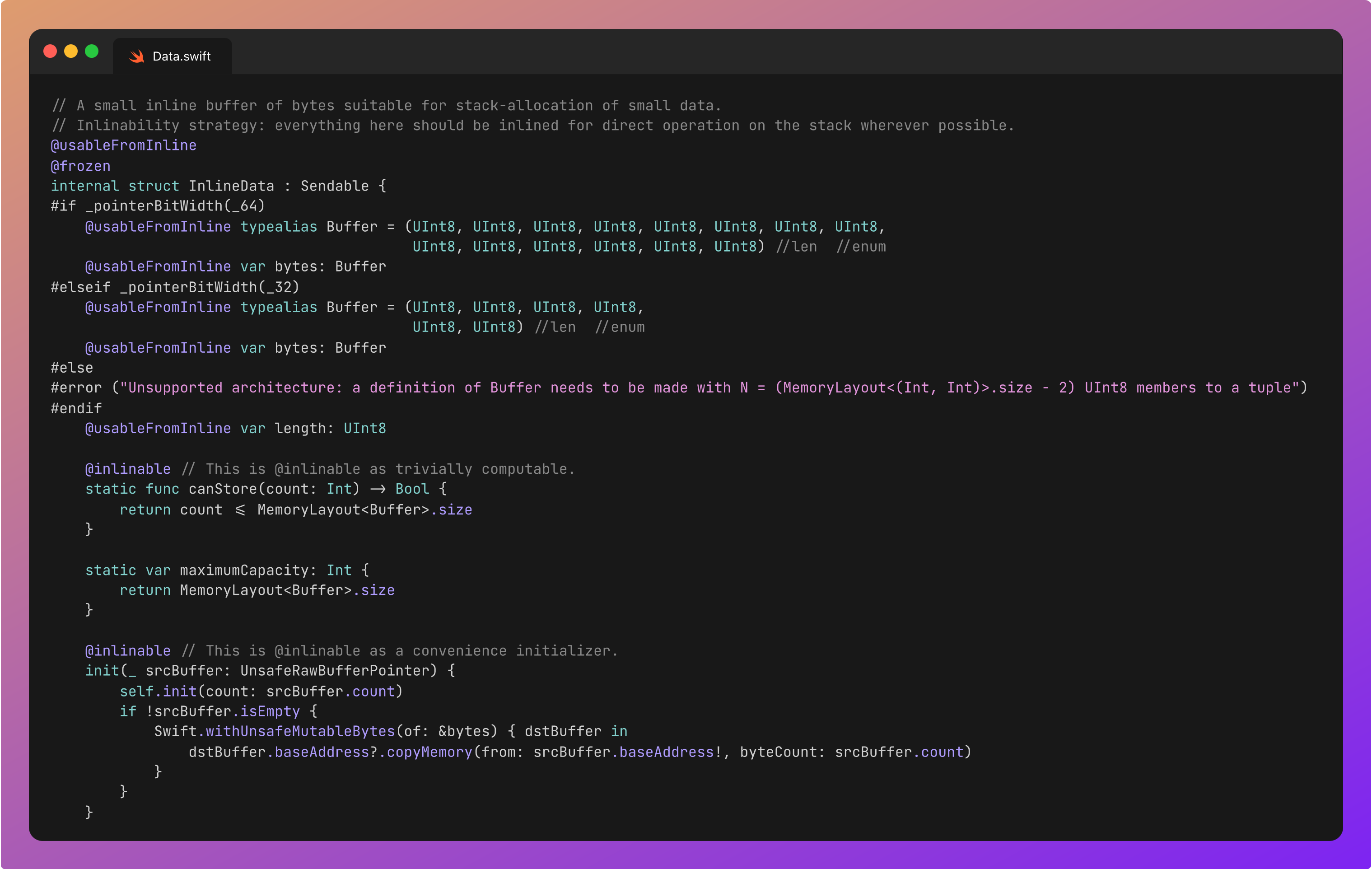
The function canStore(count:) checks whether a given number of bytes can fit into this inline buffer by comparing the memory layout of the Buffer tuple to the length of the data to store. If it returns true, the InlineData representation is chosen. if not, canStore(count:) is called to check the next largest _Representation:
InlineSlice
This representation stores data that’s too large to fit inline, so has to live on the heap. But, the heap data has to be small enough to define its precise location within the representation’s 2-word memory layout.
InlineSlice representation has 2 instance variables. First, it has the 8-byte pointer to __DataStorage, a reference to the underlying data on the heap.
The other property is a slice struct, with a data range of 2 Int32s. These 4-byte “HalfInts” add up to the other 8 bytes in the 2-word memory width of the data representation, allowing the enum to remain inline. This means the maximum range for InlineSlice is Int32.max, or about 2GB.
This slice defines a range on the underlying heap data (in __DataStorage) that the InlineSlice points towards.
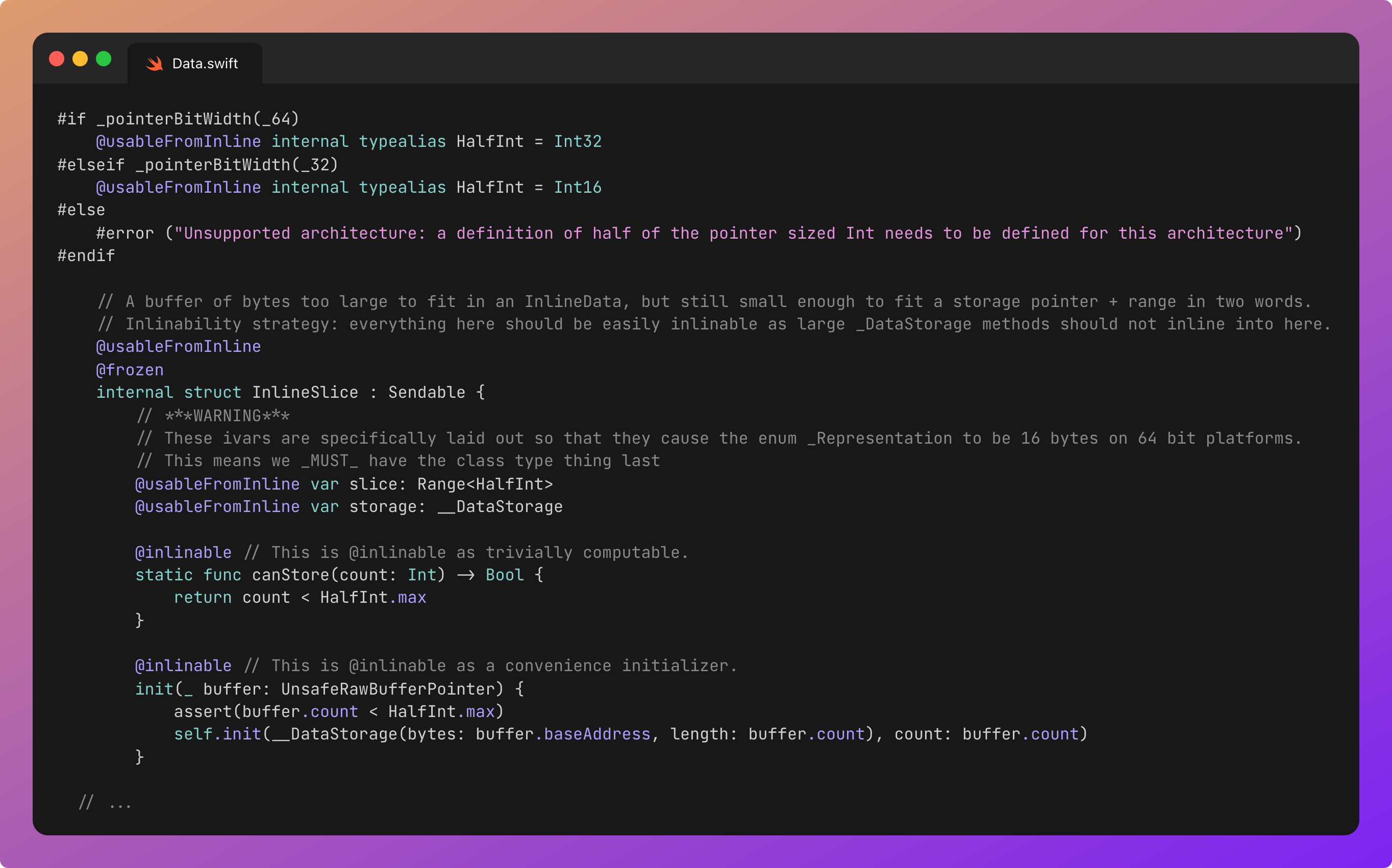
You might now be asking; “Why do we need a pointer and an Int32 range? Why not a pointer and an Int64 length, so we can store way more?”
This is another optimisation.
Multiple InlineSlices can share a common underlying __DataStorage, pointing to the same heap memory address, but representing separate subranges of this data. As an example, this optimisation might be useful in contexts like video filtering and editing, where you can manipulate various ranges of the video in different ways.
Overall, InlineSlice offers a storage range of between 14 bytes and about 2GB. It’s probably how most of your Data is represented.
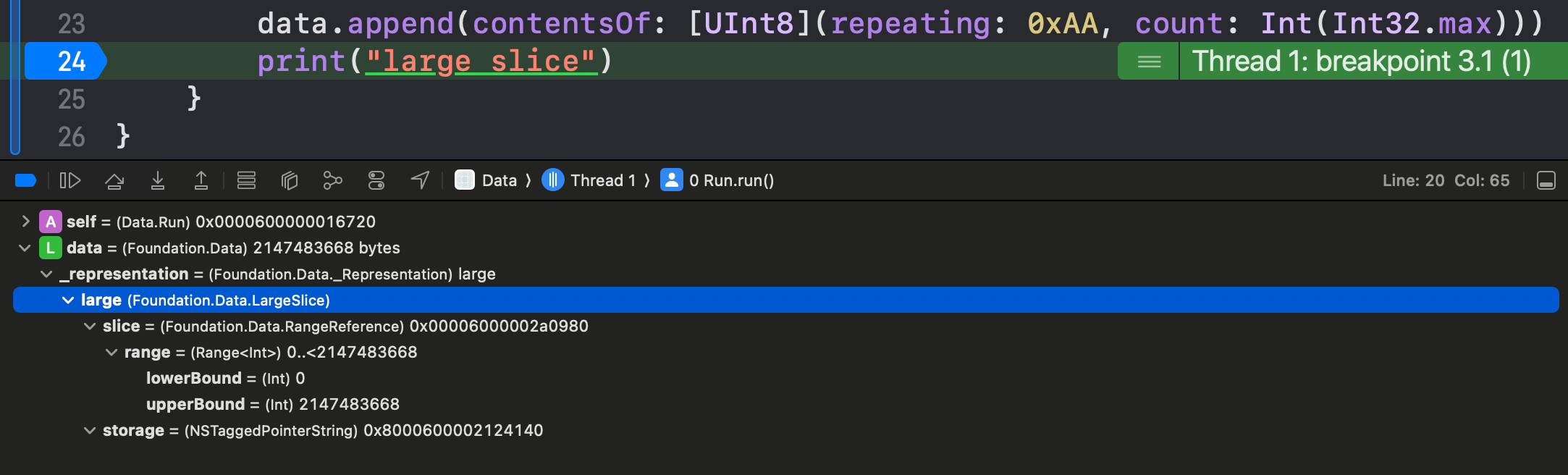
LargeSlice
As the younger generation might say, this representation is a big chungus.
It can represent slices of data with a range up to Int.max, which means ~8 exabytes on a 64-bit chip architecture. For reference, in 2023, global internet traffic was 59 exabytes. It goes without saying that this representation can comfortably contain enough data to fill the entire virtual address space on the heap.
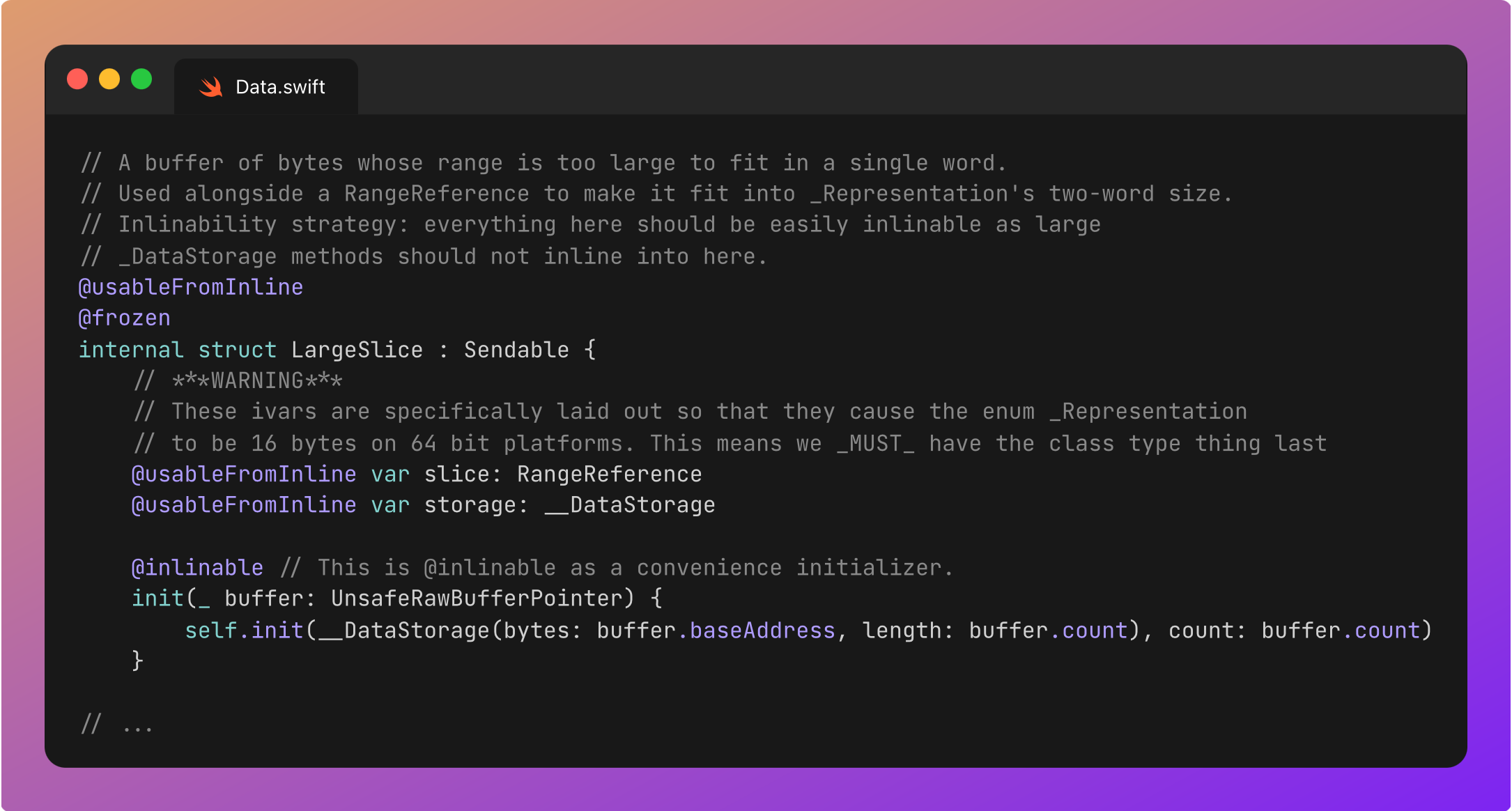
Because _Representation must be 2 words (16 bytes) wide to fit on the stack, , we can’t fit both the full 16-byte range and an additional reference to the actual storage.
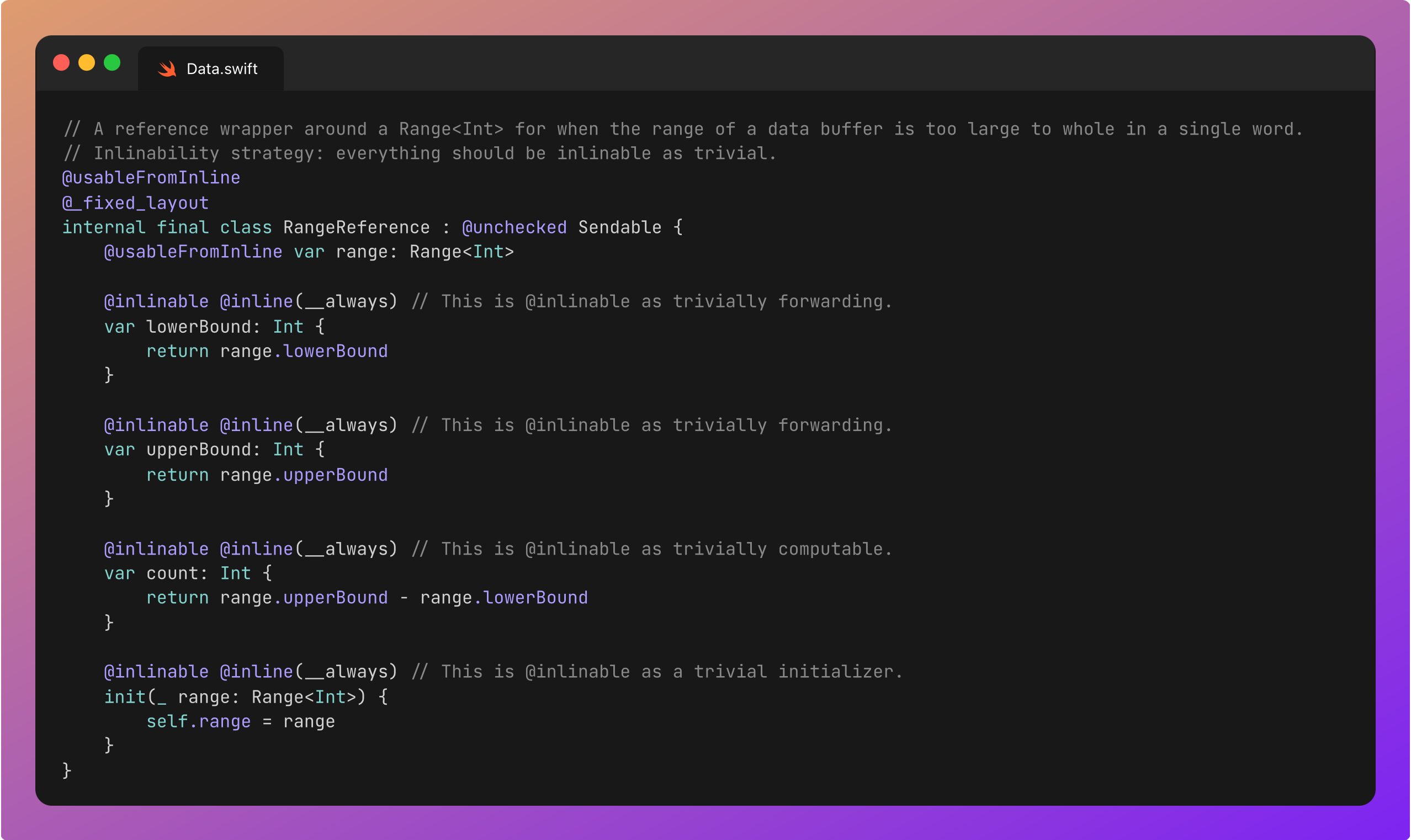
Therefore, the two instance variables are both 8-byte address pointers, to the underlying __DataStorage and RangeReference.
This RangeReference is simply a reference wrapper around Range<Int>, with lots of @inlinable annotations to help the compiler optimise things.
Optimisations in Action
We can watch these optimisations in action with some very simple code and some breakpoints.
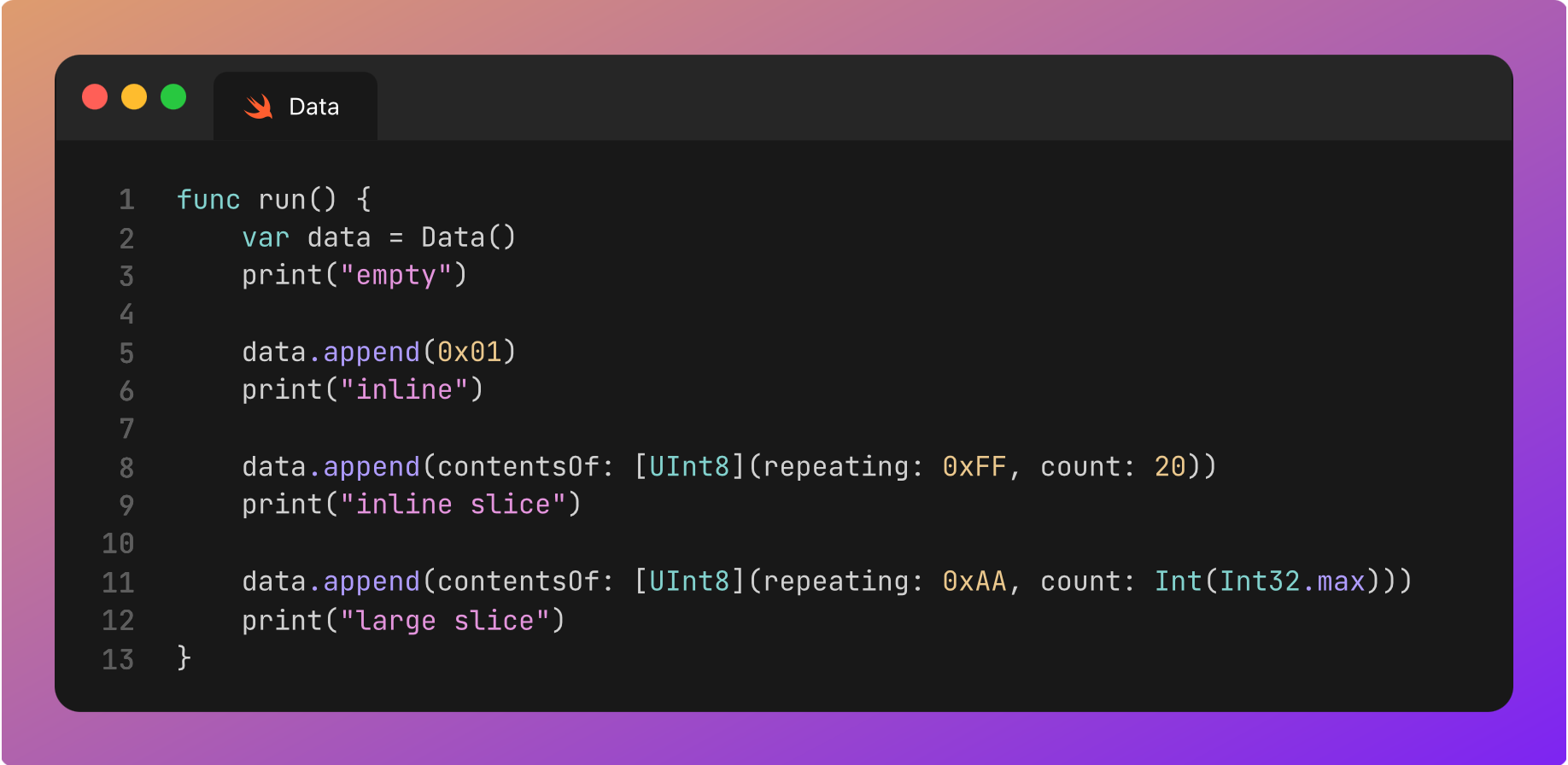
Empty
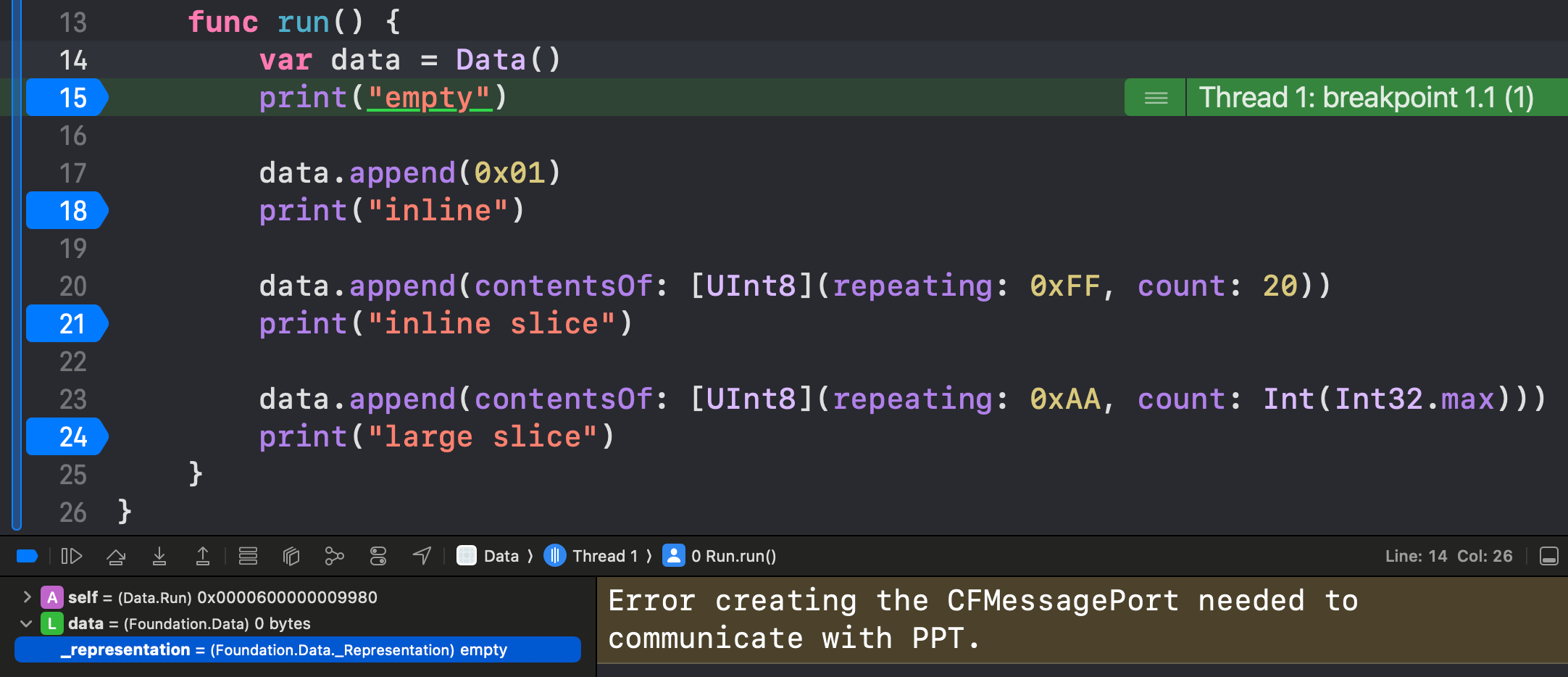
Inline
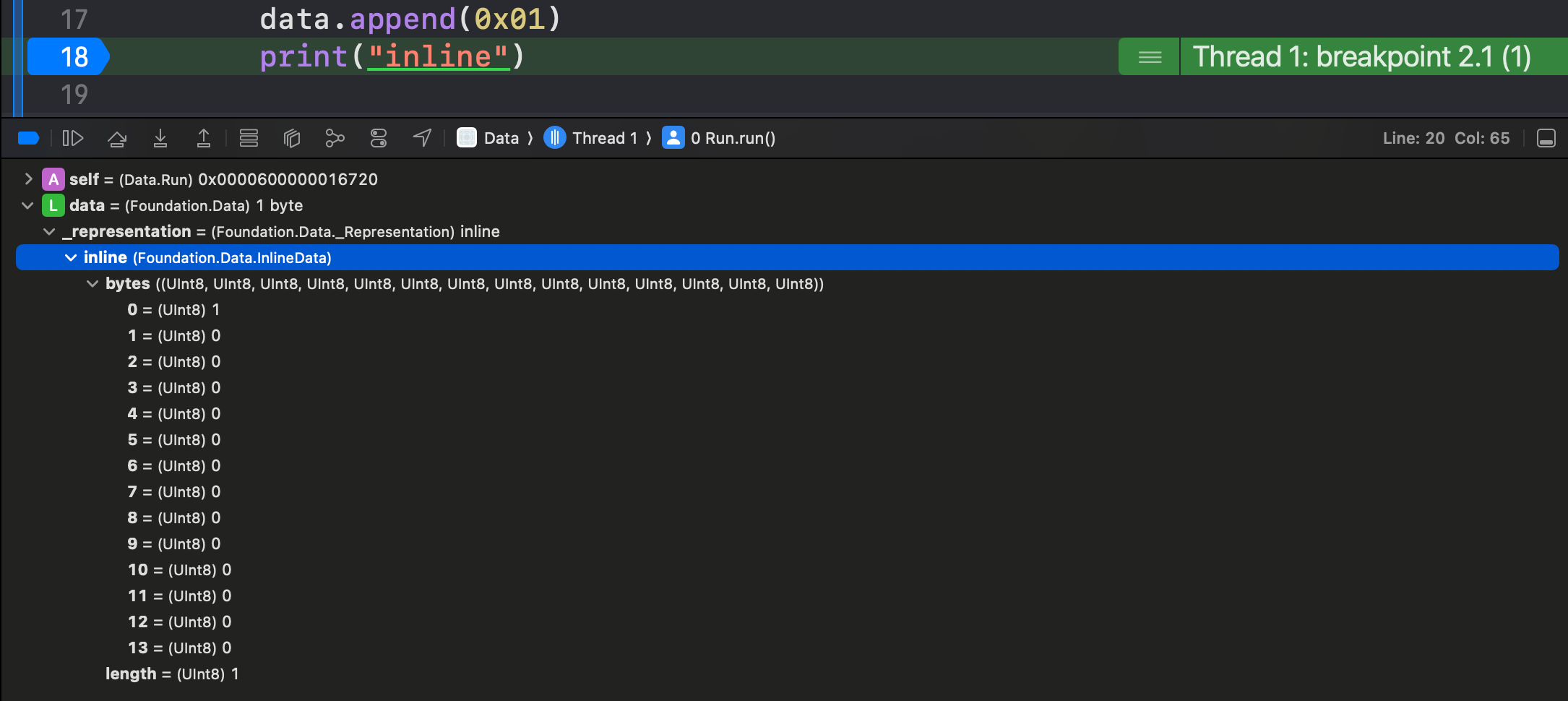
InlineSlice
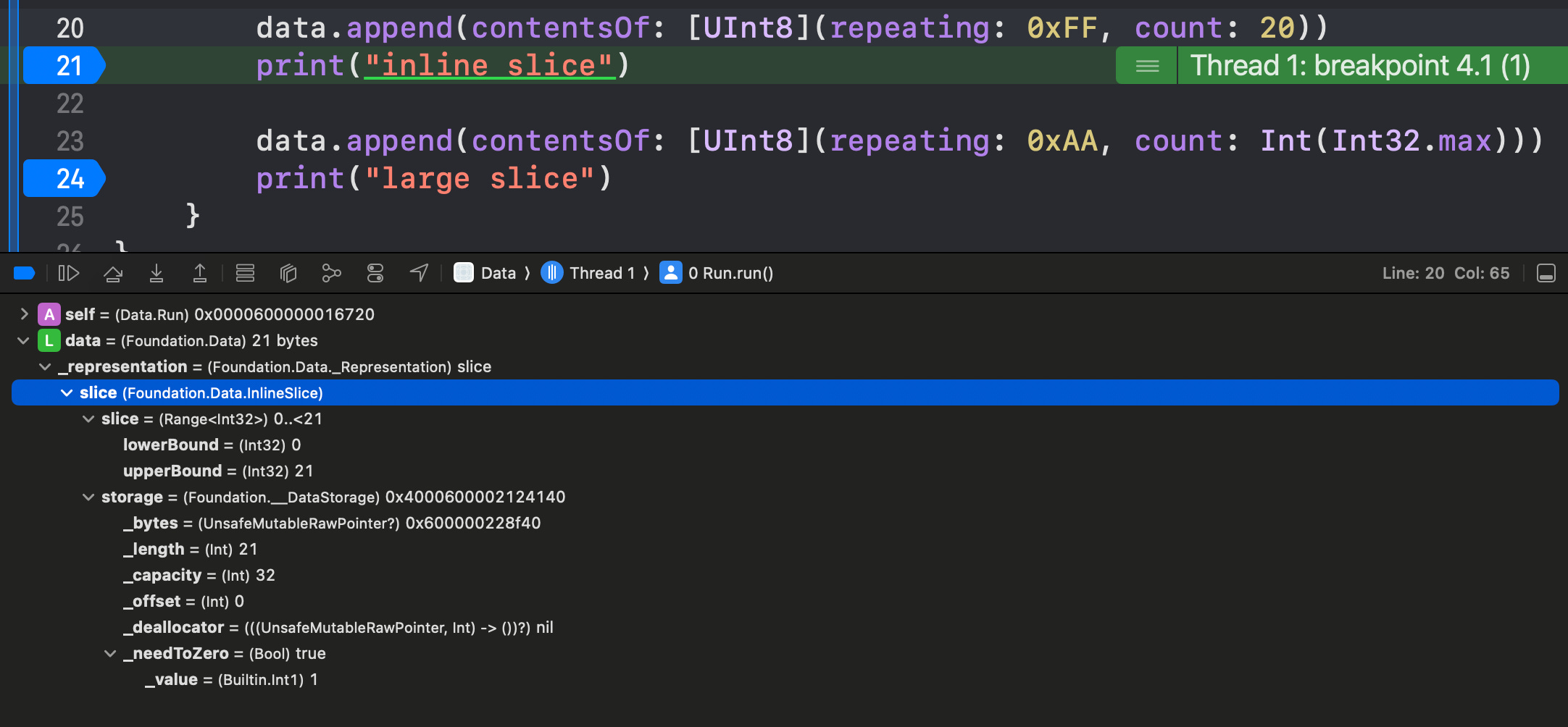
LargeSlice
Last Orders
swift-foundation is the future of multi-platform Swift development, applying ubiquitous C standard library functions to implement an API for common foundational tools that feel familiar to Apple platform developers.
Data is one of the most fundamental tools in programming, giving us a portable, no-nonsense way to transform anything into anything, move anything anywhere, or store whatever we need.
The implementation of Data, on its surface, is fairly straightforward. It wraps a pointer to the heap. But the angels are in the details, and the optimisations applied to Data are a fascinating read.
Based on the size of the data to store, a _Representation is chosen. This can store the raw bytes inline, it can define a mid-sized slice of some shared data on the heap, or perhaps it references the ungodly 8-exabyte theoretical maximum size for heap data.
Regardless of the representation, it’ll always fit in a stack-allocated 2-word enum, giving predictable high performance for any job you need.
Thanks for reading Jacob’s Tech Tavern! 🍺
Subscribe to Jacob’s Tech Tavern for free to get ludicrously in-depth articles on iOS, Swift, tech, & indie projects in your inbox every week.
Paid members unlock several extra benefits:
Read Elite Hacks, my exclusive advanced content 🌟
Read my free articles 3 weeks before anyone else 🚀
Access my brand-new Swift Concurrency course 🧵.