
How To Release Without Fear
Achieve confidence with Health Checks™ 🚑

We can’t all afford platform teams and release trains, but perhaps we’ll get there one day if we can avoid committing prod incident seppuku 🗡️.
Subscribe to Jacob’s Tech Tavern for free to get ludicrously in-depth articles on iOS, Swift, tech, & indie projects in your inbox every week.
Full subscribers unlock Quick Hacks, my advanced tips series, and enjoy my long-form articles 3 weeks before anyone else.

Startups are a rollercoaster.
Move fast and break things is the mantra, and sacrificing (some!) quality to maximise velocity is the name of the game. YOLO-ing a release to 100% of your users at 11pm is part of the fun.
Releasing is the hardest problem on mobile.
You can’t just deploy a fix like you can on web or backend. Apple and Google gate your releases via App Review™, so you have no guarantee of shipping your fix quickly. Without dedicated QA, your first sign of a production incident might just be when Twitter blows up.
This is cute when you have a few hundred DAUs (daily active users). You and your cofounder can apologetically ship a release over the weekend to your understanding cult of early adopters.
The risk profile changes as you scale up.
At about 10-100k DAUs, production incidents become existential: if a core feature is inaccessible, there’s a widespread crash, or your users all get logged out, growth nosedives and you’ll have to go back to Amazon.

I’ve spent 5 years in mobile at early-stage startups, and I’ve lost a lot of sleep to P1 alerts. For my own sanity, I’ve created a few novel approaches to app releases so we can move fast without breaking things.
Not today, Bezos.
The Gold Standard

Like all starry-eyed entrepreneurs, we should first look at what big tech does so we can cargo-cult.
But, like all jaded curmudgeons, we need to temper the big ideas with what’s effective for a company of our size.
The big players in mobile apps like Meta, Uber and Revolut have a lot in common: They have lots of engineers creating lots of PRs. Changes are tested and merged in parallel. New features are hidden behind feature flags, allowing for phased rollout or rollbacks. Metrics are gathered and analysed by eager data analysts.
Releases are cut at regular intervals and rolled out with a Release Train™ 🚂.
These track status & metrics for in-flight releases on a dashboard. Release trains visualise each step of a release going green — verifying the product works perfectly without any serious bugs or performance regressions.
A comprehensive combo of automated testing, manual QA, internal dogfooding, beta tests, and analytics ensures that the build landing in the app store is robust (and won’t haemorrhage revenue).
We don’t have a dozens-strong mobile platform team. Our engineers all wear multiple hats. Our HR guy is a web page. Payroll runs when I shout, across the room, at my cofounder.
We need to find what works for a startup.
The Pragmatic Startup

Your release strategy serves 2 conflicting goals:
Minimise risk to the business. Avoid widespread production incidents, minimise crashes, and don’t releasing a gamebreaking bug.
Minimise time spent releasing. Every hour you spend on QA is an hour that could be spent building.
As with all things in computer science, it’s a trade-off: your strategy determines where you draw the line.
There’s a Pareto principle at play: we aren’t Facebook (yet!), but you can get 80% of the value of release trains with 20% of the effort through smart automation.
Much like profiling your own code, it’s critical to understand your own business context to work out your own risk profile. At my last startup, we had two broad categories of mobile prod incidents:
Schoolboy errors that should have been caught in testing 🤦♂️
Subtle bugs which couldn’t be reliably reproduced 🕵️♂️
These two different classes of problem had different solutions: one manual; one automated.
Unavoidable Manual QA
I’m hesitant to even mention this because of how obvious it sounds, but it’s what works for me.
Every app has core flows. Flows which, if they are broken, you are screwed.
Onboarding — screens every new user sees
Authentication — creating a new account, logging in & out
For a social app — any flows around friends & sharing
For a finance app — anything involving a transaction
For a camera app — everything around taking & saving photos
For a shopping app — browsing & purchasing products
You get the idea. What’s helpful is to enumerate the core flows on a shared checklist (Notion, Confluence, Apple Notes, or Slack are all good) and having a couple team members sign off each flow for each release.
A side bonus of this approach is, you regularly experience all the main flows of the app yourself. It’s extremely easy to stay on top of minor bug-fixes if you ticket them up as soon as you see them.
Once you get the hang of it, these can be run through in under 15 minutes, which if you’re releasing ]][]]]]\
=[\
\[\
Sorry, my toddler woke up next to me and wanted to help.
Nice helping, Lyra.
This can normally be done in under 15 minutes, which if you’re releasing each week is a pretty fair time commitment.
I’ll address the elephant in the room:
“What about automated testing?”
You should decide what level of automated unit and integration testing is appropriate for your app. These should run on your CI for each pull request.
Frankly, however, I find UI testing and E2E testing has limited benefits—even on big projects. They add an enormous maintenance burden, and drastically increase the duration of your pipelines, and in my whole career they have found me zero bugs.
Your mileage may vary. I’ve had some success with Maestro, a cross-platform automation testing tool, to set up automated UI tests against a flakey third-party dependency in our app. A few days invested in shoring up risky flows as part of your release process can be a worthwhile investment.
When the downside risk of missing a nasty bug is so steep, forcing yourself to spend 15 minutes per release cycle on manual testing is a small price to pay. Automation is nice, but any good computer scientist will tell you never to trust machines.

Health Checks™
Manual QA only takes you so far. It’s great for those 100% reproducible “schoolboy errors” — issues that will only get into production if you’re being careless.
A far more insidious incident can slip past QA in a hectic startup environment and onto your users. The classic bug which “works fine on my machine”.
At my last startup, I developed an approach which served as a safety net to find these before it’s too late.
Tracking with Metrics
Perhaps the bug only happens 20% of the time; maybe it only rears it’s head in older iPhones or Android devices; it might be a crash which only occurs between 8 and 10pm; you might see total failure of the payment flow but only from Iranian IP addresses*.
*this one actually happened with our contractor once; damn sanctions.
These might decimate your userbase, but you won’t know until it’s too late.
This is where statistical analysis comes into play.
We need to quantify our app quality.
You are already collecting analytics and logs. This might be a combination of backend system traces, Mixpanel, or some first-party solution. You should also have crash reporting somewhere in the mix.
You should already be using phased rollout to minimise risk with releases. The iOS App Store and Google Play Store both support this. You can automatically release your app to 1%, 2%, 5%… up to 100% of users over a week.
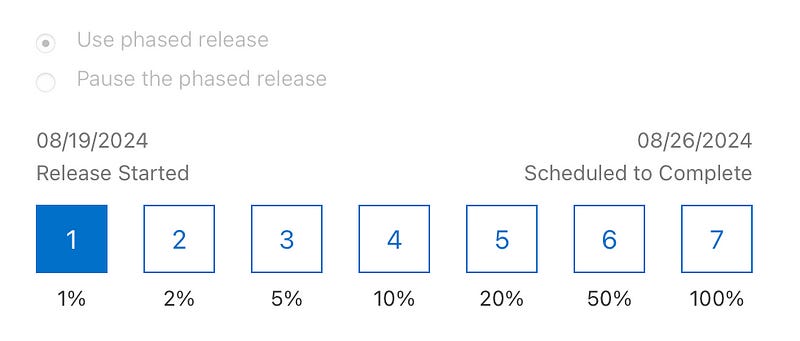
We can combine logging with phased rollout to create Health Checks™: at a specific rollout %, compare some core metrics for the new version against the previous app version.
If you spot a sudden sharp regression in your onboarding, you can pause rollout at 2% and distribute a hotfix.
Health Checks™ in Action
Here’s an example of SQL we used with Google Cloud’s BigQuery to measure a simple ratio: first install to registration. This simple statistical check identifies regressions in onboarding and auth:
-- Version numbers --
DECLARE current_version_number STRING DEFAULT '2.2.0';
DECLARE previous_version_number STRING DEFAULT '2.1.0';
-- Calculate ratio of installs to registrations --
SELECT
version_number,
SUM(CASE WHEN event_name = 'install' THEN 1 ELSE 0 END) AS total_installs,
SUM(CASE WHEN event_name = 'registration' THEN 1 ELSE 0 END) AS total_registrations,
SAFE_DIVIDE(SUM(CASE WHEN event_name = 'registration' THEN 1 ELSE 0 END), SUM(CASE WHEN event_name = 'install' THEN 1 ELSE 0 END)) AS registration_percentage
FROM
production.analytics_events
WHERE
event_name IN ('install', 'registration')
AND version_number IN (current_version_number, previous_version_number)
-- Filter within the last 14 days --
AND event_timestamp >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY)
GROUP BY
version_number
ORDER BY
version_number DESC;The output to this query might look a little like this:
+---------+---------+--------------+------+
| version | installs| registrations| % |
+---------+---------+--------------+------+
| 2.2.0 | 1000 | 680 | 0.68 |
| 2.1.0 | 90000 | 60000 | 0.67 |
+---------+---------+--------------+------+Here, we can see the proportion of installs to registrations hasn’t changed much, so we can safely assume there’s no serious regression in the onboarding process or authentication from version 2.1.0 to 2.2.0.
If it looks like this, you might want to pause your rollout and investigate:
+---------+---------+--------------+------+
| version | installs| registrations| % |
+---------+---------+--------------+------+
| 2.2.0 | 1000 | 240 | 0.24 |
| 2.1.0 | 90000 | 60000 | 0.67 |
+---------+---------+--------------+------+The most basic form of Health Checks™ live in a shared Notion doc, with templated SQL queries for core flows to copy-paste into your analytics console. You manually adjust the version numbers as required.
Analytics solutions like Mixpanel usually allow you to create live dashboards to visually spot regressions on key metrics.

These are an enormous help when starting with zero safety checks, but they get tedious after a while.
The next stage is automating the process.
Automation
Earlier, I alluded to smart automation that can achieve the 80% results of a big tech release train with 20% of the effort. There are different tiers of automation we can apply to Health Checks™ as you evolve your release process.
You can run queries and then manually log results to Slack, alerting team members as needed. Setting these queries up initially takes some work, but then it’s simple enough that your less-technical product people can process them in minutes.
We can very easily automate this process to save a ton of time each release. Analytics solutions and backend infra usually exposes API access. We can set up command line tools to enter version number, rollout percentage, and run the queries automatically, then flag any warnings to the team.
Sometimes, API access isn’t forthcoming. For these tricky situations, it’s a great opportunity to whip out your webscraping and bash scripting tools.

With a Slackbot, you could even kick off this entire process from a chat message or cron job, and automate the alerting by @ing the relevant teams.
Once you’ve agreed on your process, release confidence is disseminated throughout the team via chat messages:
🚑 iOS v2.2.0 release health check:
- 📈 Rolled out to: 10%
- ✅ Crash-free users: 99.9%
- ✅ Crash-free sessions: 99.8%
- ✅ Registration rate: 72%
- ⚠️ Purchases per session: 1.3 (1.1.0 was 1.4) - @mobile-devs
- 🔥 Checkout success rate: 82% (1.1.0 was 97%) - @mobile-devs
- ✅ Social sharing rate: 24%With Health Checks™, we have boiled down the amorphous uncertainty of unanticipated production incidents into a simple traffic-light system. Your whole team can digest the reports and build up an earned confidence with each release.
My Own Experience
The release strategies I detail here didn’t come out of thin air. I gradually developed these approaches across my time at several startups. I’m scarred by dozens of production incidents but undeterred in my quest to ship fast.
I have personally never found a bug with a UI test. I’ve lost days of my life to their maintenance, and longer waiting for them to finish on the CI.
A small amount of manual QA investment is a pretty small price to pay—I won’t bet the house that I didn’t break anything all week. It’s okay to de-risk your business by baking in annoying overhead — that’s what every large company in the world does*.
*except Crowdstrike.
Health Checks™ start as a manual process while you feel out the funnels and flows for which you need extra confidence. Queries can be added, changed, or removed as you learn what works. Once you know what to look for, you can automate and accumulate saved time with every single release.
During a phased rollout, you might find your Health Checks™ giving weird numbers at 2%. This is because the variance in data is higher with a lower sample size, so the 2% of users on the new version can usually have a higher or lower number than normal.
Therefore, don’t be scared if you see a few ⚠️ in your results — just stay vigilant! With repeated Health Checks™, you develop a spidey-sense for the warnings which are actually worrying vs a self-correcting statistical anomaly.
As the complexity of your app grows, some bugs become harder to spot early, so Health Checks™ become an increasingly important part of your company release train.
Other Release Tools
This isn’t exactly novel research, but I’ll briefly cover some other important tools in your release tool-belt.
Feature Flags
These are remotely-configured values which allow you to enable or disable a feature in your production app.
These are commonplace in all app companies, since most engineering teams tend to merge straight into main these days. Releases are cut on a regular cadence, including all the merged code from incomplete features.
With feature flags, we can enable these incomplete features in development builds and hide them in production. We can facilitate beta testing by enabling the flag for specific cohorts of prod users and get early feedback.
There are tons of tools for this, but usually I’ll end up defaulting to Firebase Remote Config. Just don’t go crazy or you might find yourself in feature flag hell.
Alerting
Look — it’s not 2010 anymore; you can generally expect to get an expedited hotfix out in under 12 hours. But the faster we know something is wrong, the shorter this cycle time, and the smaller the impact.
If you suspect your team is getting too well-rested, you can implement alerting through Slackbots, PagerDuty, Firebase, or Sentry. These will wake your team up to tell them as soon as something is amiss, so they can get to work ASAP on pausing rollout and shipping a hotfix.
Conclusion
This piece is ostensibly about my experience at startups, however the techniques apply to any business releasing a nascent app into the wild.
You want the best chances of success, and therefore you want to de-risk your business by protecting your app from production incidents as you scale up.
Every business compromises between speed and quality. There is a place in the ecosystem for janky 2,000-line view controllers as well as beautifully abstracted factoryfactoryfactories.
The best startups are pragmatic — confident in releases, without spending any more time than necessary on manual QA. Health Checks™ and automation allows engineers to sleep easy (or, if you have alerting set up, maybe not) during phased rollouts.
We can’t all afford platform teams and release trains, but perhaps we’ll get there one day if we can avoid committing prod incident seppuku 🗡️.
If anyone knows a patent lawyer, let me know, I keep calling them Health Checks™ but don’t really know what a trademark is.
Thanks for reading Jacob’s Tech Tavern! 🍺
If you enjoyed this, please consider paying me. Full subscribers to Jacob’s Tech Tavern unlock Quick Hacks, my advanced tips series, and enjoy my long-form articles 3 weeks before anyone else.

Excellent article. My team does manual release smoke testing as we’ve found UI tests next to useless. I think one thing I always try to consider is the value of the automation that we’re building i.e. are the benefits worth the cost to the business. I think this is especially in key in small teams/companies.