
High Performance Swift Apps
Seek and destroy the bottlenecks in your code

From The Vault™ this week is one of my favourite ever posts. It was certainly the most fun I’ve had building and writing something.
I’m taking you through my patented 3-step process to drastically improve the performance of your app. Along the way, we’ll find a few very interesting algorithm and concurrency puzzles along the way.
I am finally releasing the source to turn this into a code-along tutorial!
→ Get the before sample code.
→ Get the after sample code.

Two weeks ago, I released Check ‘em: The Based 2FA App.
The concept was pure: a two-factor authentication app which sends you a notification whenever a really great number shows up. Tap the notification to permanently add it to your collection.
The kind people of Reddit enjoyed my write-up — from idea, to proof-of-concept, to release — enough to propel me to #3 on r/programming.

Check ‘em calculates millions of 2FA codes into the future, processes each number to determine if it’s interesting, and schedules the interesting codes as push notifications — GETs.
v1.0 works pretty well, but today I’m going to focus on performance.
My app performance evaluation process has three steps:
Test on a real device to identify user-facing problems.
Profile the app using Instruments to identify bottlenecks.
Implement code improvements using 1) and 2) as our guide.
This find-problems-first approach avoids bike-shedding, keeping the focus on the real bottlenecks.
“Any improvements made anywhere besides the bottleneck are an illusion. Astonishing, but true! Any improvement made after the bottleneck is useless, because it will always remain starved, waiting for work from the bottleneck. And any improvements made before the bottleneck merely results in more inventory piling up at the bottleneck.”
― Gene Kim, The Phoenix Project
This approach helps me avoid wasting time on general code improvements that don’t move the needle for our users (so the singletons are here to stay — sorry not sorry).
Testing On-Device
Device — iPhone 15 Pro
OS — iOS 17.2.1
Processing speed
The big, glaring performance problem is exactly where you’d expect: processing your numbers while computing 2FA codes. This processing runs every time you enter the app, make a change to your 2FA accounts, or update your choice of GETs.
TOTP calculation itself is a non-trivial function, involving byte manipulation, string creation, and cryptographic operations. These codes are then checked for several kinds of interestingness, before scheduling push notifications for the most interesting codes.
This processing is pretty fast when a user has common GETs enabled, such as quads (e.g.004444), or palindromes (e.g. 123321). Check ’em runs until it has scheduled 64 notifications (the limit on iOS), so it doesn’t need to calculate far into the future when there are several codes found per day.
If a user only wants to see rare GETs, such as quints (e.g. 055555) or near-counting sequences (e.g. 012340) the total processing time can exceed 10 seconds.

Rarity increases exponentially with each tier. With only ultra-rare GETs enabled, such as sexts (e.g. 666666) or counting sequences (e.g. 012345), my screamingly powerful A17 chip takes take over a minute. This increases even more if you only choose one or two ultra-rare options.
As expected, this is by far the biggest performance bottleneck.
Time-to-first code
Since the app is pretty simple, just 1500 lines of Swift, the surface area of potential performance problems is pretty constrained.
A less offensive issue rears its head each time you launch the app fresh — while the launch itself is lightning-fast, it takes a little while for the first 2FA codes to appear.

Since a user would, ideally, be using this app for 2FA codes in their day-to-day, having useful codes snap into existence instantly would improve the user experience for the functional use case of this app.
Profiling with Instruments
Now we’ve identified the two key user-facing performance issues, we can perform a detailed analysis with Xcode Instruments. This profiling will allow us to detect the exact function calls which bottleneck our code.
Setting up Instruments
If you’re new to performance profiling, Instruments is a separate app which can be opened from the Xcode Developer Tools menu.
Our bread-and-butter Instrument is the Time Profiler, which monitors CPU cores. It samples these cores 1000 times per second, recording the stack traces of the executing functions. The resulting report shows which parts of your code are hogging compute resources.

Now we’re all set up, we can start our investigation.
Processing speed
Opening up our app, and monitoring the notification re-computation, we see some kind of async process taking up nearly 20 seconds as Check ‘em searches for interesting codes.

To make this easier to comprehend, there are 3 settings we can toggle from the Call Tree menu:
Separate by Thread splits the recorded processes up by thread rather than grouping all the same function calls together. This means if you have processes running in parallel, you see their time profiles separately.
Invert Call Tree reverses the measured backtrace. This means instead of displaying the low-level iOS system calls which run on the CPU, we can see our own functions at the top of the call stack.
Hide System Libraries cleans the report up by removing system library processes, making your own code easy to spot.
Now, we can easily see all the processing work which is happening on a background thread as we expect.
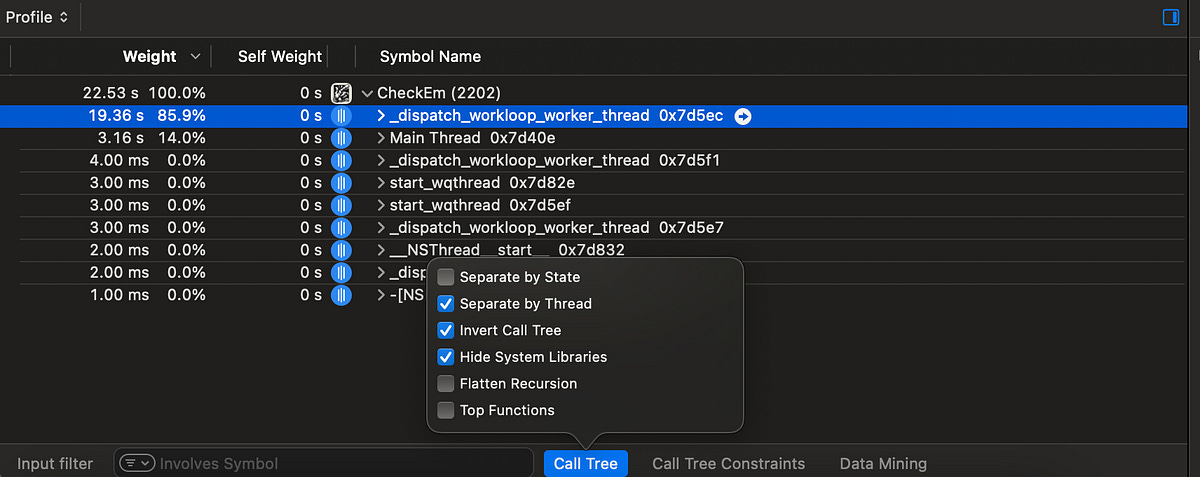
Our TOTP generation uses a non-trivial, but very well-specified algorithm. If I’d invented a way to speed this up, I’d be writing this article on from somewhere hot, on a yacht.
What I’m trying to say is, we’re not likely to find a shiny new algorithm to speed up this TOTP generation process. Therefore, we firstly want to improve anything slower than the OTP.init() method.

We’ve found the smoking gun. The slowest calculation by far is checkThoseSexts(), which wraps a regex that appears to be ridiculously computationally expensive.
extension String {
func checkThoseSexts() -> Bool {
(try? /(\d)\1\1\1\1\1/.firstMatch(in: self)) != nil
}
}When I also check for quints and quads, which use similar regexes, they also substantially outweigh the TOTP calculations.
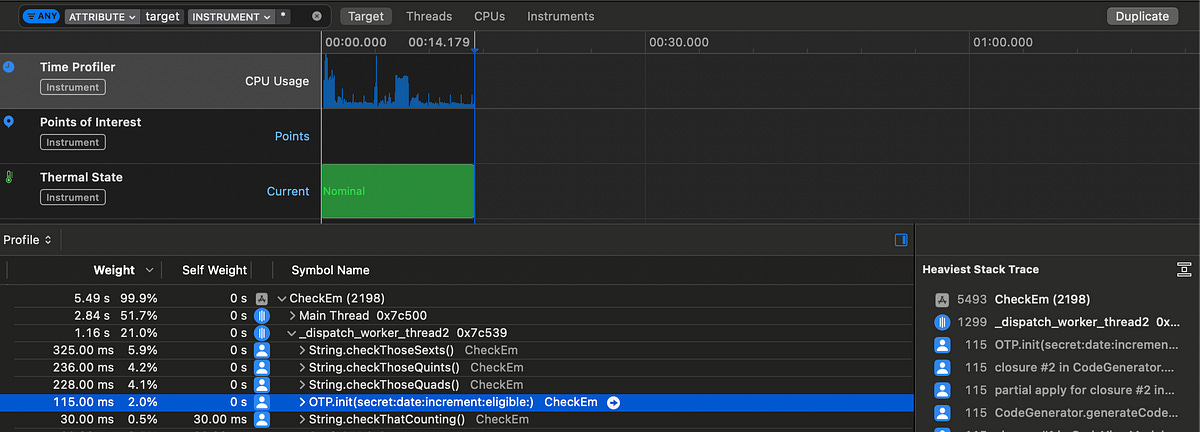
We’ve got a pretty clear indication that swapping out the regexes for alternative approaches could approximately double performance.
This analysis helped me realise something further: this heavy processing is running serially on a single background thread, with pretty much all the heavy work offloaded to _dispatch_workloop_worker_thread, created by the Swift Runtime from my high-priority detached Task.
This means just a single CPU core is responsible for generating TOTPs and checking their interestingness. If we’re clever about it, this process is dying to be parallelised.
Time to first code
The other user-facing problem is the relatively slow time between opening the app and seeing a useful 2FA code displayed.
Since we know exactly what start and end points in our code to look for — app launch up to the first displayed code — we can profile this problem with a blunter tool: print() statements and timestamps.
07:35:54.2640 - App init
07:35:56.0280 - Code displayedThe app currently takes a massive 1.764s between initialising the app to seeing a useful 2FA code. Following the code paths from launch to code generation, we get a clearer picture:
07:50:10.5640 App init
07:50:11.1980 On appear
07:50:11.2290 Set accounts
07:50:12.1630 Refresh accounts
07:50:12.1640 Code displayedThis shows two relatively long waits:
The time between app initialisation and
onAppearfiring on the main view.The time between setting
Accountsin the view model and refreshing them to get TOTP codes.
The keychain operation to fetch accounts, and the subsequent code generation step, are actually pretty quick, so don’t substantially impact the total time.
Now that we’ve identified the key performance bottlenecks, we finally can start to make some targeted code improvements.
Code Improvements
Our basic run-through of Check ‘em found two performance issues:
Processing millions of TOTPs and checking for interestingness.
Slow loading of the initial 2FA codes.
Based on our detailed analysis, we identified 3 specific improvements we can make:
Replace the regexes used to assess interestingness with more efficient algorithms.
Introduce parallelism to the TOTP and interestingness calculations.
Make the initial code generation run sooner after launch.
Let’s see how much speed we can squeeze out of this app!
Efficient algorithms
The slow regexes are the first big bottleneck we spotted using Instruments, taking up more than 50% of total processing time.
Let’s benchmark our results using only ultra-rare GETs in the computation.
Because these are so rare, the CPU needs to crunch 100x as many TOTPs to find these compared to common GETs, so finding 64 interesting GETs takes far longer.
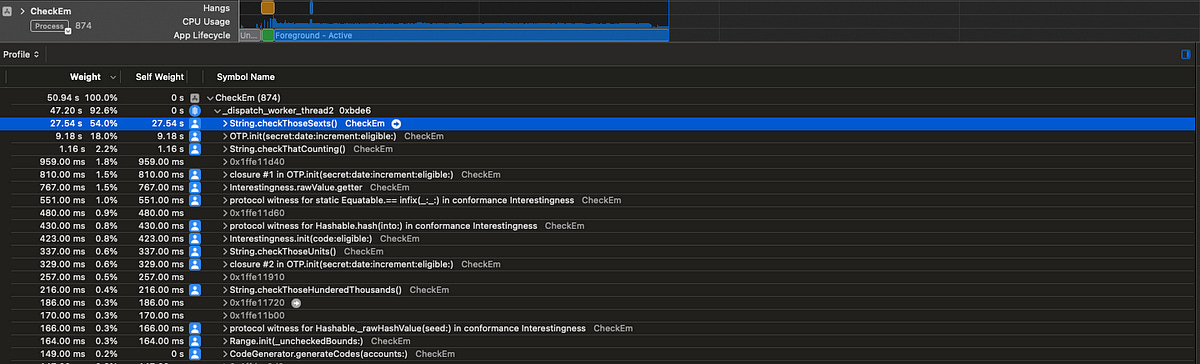
We have our time to beat!
That’s 47s spent processing on this background thread. Here’s my first alternative to the regex, using a simple string matching approach.
func checkThoseSexts() -> Bool {
checkRepeatedDigits(count: 6)
}
// Nicely factored so I can check for quads & quints
private func checkRepeatedDigits(count: Int) -> Bool {
(0...9).map {
String(repeating: String($0), count: count)
}.contains(where: { self.contains($0) })
}In one single function change, the sextuple check itself is more than 10x faster, slashing the total computation time down to 21s— more than twice as fast!
Such is the power of focusing on bottlenecks.

I’ve written some neat code, but it’s actually pretty inefficient — we’re performing a heap allocation of 10 strings (from 000000 to 999999), followed by an O(n) string matching operation every time we check a single TOTP for sextuples. Therefore this operation is still the second-heaviest in play (after TOTP creation itself).
There’s an alternative, gruggier, approach, which might make life even easier — hardcoding a list of numbers. This avoids repeating the expensive string allocations. We can apply the same approach to the heavy operations that look for quads, quints, and counting.
// Interestingness.swift
func checkThoseSexts() -> Bool {
Self.sexts.contains(self)
}
private static let sexts: Set<String> = [
"000000",
"111111",
"222222",
"333333",
"444444",
"555555",
"666666",
"777777",
"888888",
"999999"
]
func checkThatCounting() -> Bool {
Self.counting.contains(self)
}
private static let counting: Set<String> = [
"012345",
"123456",
"234567",
"345678",
"456789",
"567890"
]We’ve handily eliminated the biggest bottleneck: The checkThoseSexts method has gone from a cumulative time of 27.54s to just 899ms — a 30x increase in speed.

checkThoseSexts()Now, this gives me a bright idea.
There are only 1 million possible 6-digit TOTPs. Perhaps, as an upper bound, 1 in 100 are interesting*.
*The most common interestingnesses, such as palindromes (like
123321) and repeated threes (like123123), are 1 in a thousand. Therefore, 1 in 100 is a pretty reasonable upper estimate for interestingness.
Ten thousand numbers isn’t that big. It wouldn’t take very much processing power to hold them in an efficient data structure such as a dictionary, keep this in memory, and look up interestingness with a single O(1) operation.
Additionally, this offloads the computation from users to my trusty M1 MacBook, and saves the environment.
But, while this is a bright idea, this isn’t the bottleneck! Therefore, I’m going to regretfully leave it for now. TOTP calculation now takes up the vast majority of processing time.
This is an appropriate time to invoke our CPU cores.
Parallelism
All our computation is currently performed on a single background thread. I’ve been wondering how I might improve this.
The natural idea would be to ‘chunk up’ the TOTP calculation, and put each chunk on different threads. But how would we apply this chunking?
We can’t necessarily do it by day, by week, or by month, since we might end up running lots of computation that we can’t use — we can only schedule a maximum of 64 notifications at once on iOS.
Let’s find an approach which minimises complexity.
Let’s use the CPU architecture as a guide: modern iPhone processors contain 6 cores, so let’s aim to use 6 simultaneous chunks. We can use taskGroup to set up these 6 parallel processes.
// CodeViewModel.swift
otpComputationTask = Task.detached(priority: .high) {
await withTaskGroup(of: Void.self) { group in
(0..<6).forEach { startingIncrement in
group.addTask {
CodeGenerator.shared.generateCodes(
accounts: accounts,
startingIncrement: startingIncrement
)
}
}
}
}We can then run these 6 parallel processes to calculate every 6th TOTP code into the future. Each process ends when it has found 1/6th of the total interesting numbers.
// CodeGenerator.swift
func generateCodes(accounts: [Account], startingIncrement: Int) {
var increment = startingIncrement
var interestingCodesCount = 0
while Double(interestingCodesCount) < (Double(Constants.localNotificationLimit - 2) / 6).rounded(.up) {
// TOTP calculation ...
increment += 6
}
}This seemed to process faster, however it completely locked up our UI with hangs. The app was near-frozen and unresponsive while it processed our TOTP codes.

This is because I am forcing 6 high-priority processes to happen at once, so the main thread has to share rendering cycles with this expensive computation.
This would be even worse on many older iPhones that don’t have a full 6 cores available — therefore, we should limit the number of processes to one per CPU core, and leave one core spare for the UI thread.
ProcessInfo.processInfo.processorCount - 1 Now we’re talking! This gives us a much healthier 5 threads of heavy, chunked-up computation and one very calm UI thread, without any hangs to write home about.
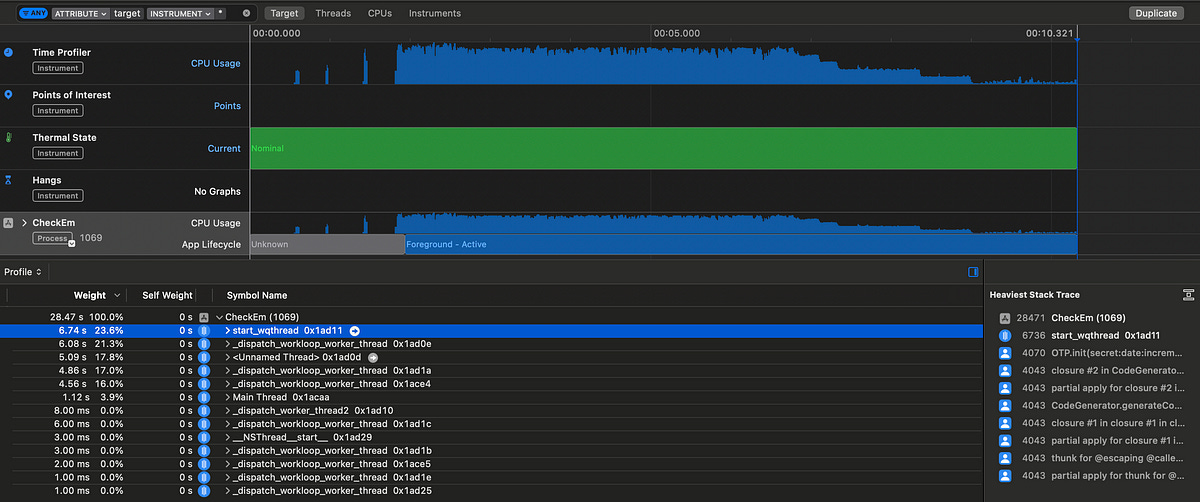
This parallelism has taken our longest-running thread from a heavy 15.37s process down to, at worst, 6.74s — a 56% decrease.
We are using 5 cores. Why isn’t this neatly 5 times faster?
Maths and Actors
There is still an issue with our approach: each of our n threads independently searches for interesting numbers, until it has found 64/n interesting numbers.
The fastest thread might find 64/n codes all within the next 2 weeks, and the slowest thread could potentially be calculating forwards until next month if it’s unlucky — TOTPs are spaced 30 seconds apart and the interestingness of their codes is randomly distributed.
This problem is twofold:
Firstly, we’re missing potential numbers by overcounting on some threads and undercounting on others.
Secondly, since our threads can take very different times to process, we are not utilising our CPU as efficiently as possible compared to if each thread took the exact same amount of time, spread across all CPU cores.
Perhaps, instead of working from an offset, each thread simply runs independently and calculates the next un-calculated code. Therefore, we need a way to safely share state between these threads and ensure each new TOTPs calculated uses the next un-calculated 30-second date increment.
Swift offers a neat solution to this problem with Actors, which enforce serial access to their state.
// CodeIncrementor.swift
actor CodeIncrementor {
private var _increment: Int = 0
func increment() -> Int {
defer { _increment += 1 }
return _increment
}
}Compared to our first attempt at parallelism, which allowed each thread to run wild calculating every 5th TOTP independently, this approach requires coordination between our processes.
This coordination adds overhead — each process is a little slower individually because they might need to wait to call increment() on the actor’s Serial Executor, as only one process can call this at once.
Consequently, each time increment() is called, the thread is guaranteed to safely get the correct offset, so we only ever calculate the next un-calculated TOTP code to assess its interestingness.
// CodeGenerator.swift
func generateCodes(accounts: [Account], incrementor: CodeIncrementor) async {
// ...
while Double(await incrementor.codes) < (Double(Constants.localNotificationLimit - 2)) {
let increment = await incrementor.increment()
// Generate TOTP from date increment ...
}
}Let’s measure how this performs!

This Actor-based approach leads to several more threads in-flight at once. Swift concurrency aims to have approximately one thread running per CPU core, in line with our original parallelism goal, and manages threading itself using a system-aware cooperative thread pool.
The total cumulative execution time given in instruments is the sum across each thread. This is of course not representative of the time our users are waiting — to get a proper measure, let’s crack out our trusty timestamps again and measure the total speed for calculating interesingness for ultra-rare GETs.
Original speed without parallelism
23:10:55.2940 Computation started
23:11:09.9220 Computation finished14.628 seconds in total.
Speed using chunking and (n-1) threads
23:07:00.4700 Computation started
23:07:09.5980 Computation finished9.128 seconds in total.
Speed using Actor coordination
23:01:38.7080 Computation started
23:01:46.5300 Computation finished7.822 seconds in total.
This shows us that the additional thread coordination overhead we take on with actors is worth it — the process is more correct, it more efficiently utilises our CPU cores, and is overall makes this computation step 47% faster!
Earlier code generation
Our final piece of performance profiling, using print statements and timestamps, found two big waits before useful 2FA codes appeared to our users: waiting for onAppear in our main view; and waiting to refresh() the codes themselves.
// CodeView.swift
@State private var viewModel = CodeViewModel()
@State private var timer = Timer.publish(every: 1, tolerance: 0, on: .current, in: .common).autoconnect()
var body: some View {
// ...
.onReceive(timer) { _ in
viewModel.refresh()
}
.onAppear {
refreshUI()
}
}We are first waiting for onAppear to set up Accounts in the view model, and then waiting again for the 1-second timer to fire.
This is a pretty simple fix: decouple Accounts fetching and TOTP calculation from the view lifecycle events.
// CodeViewModel.swift
final class CodeViewModel {
init() {
timestamp("View model init")
configureAccounts()
refresh()
}
// ...This drastically cuts down the time between app launch and code generation — from 1.764s to 0.400s.
20:41:35.6890 App init
20:41:36.0830 View model init
20:41:36.0890 Code displayedNow, the codes snap into the screen almost immediately.

Conclusion
Check ‘em — The Based 2FA App was a madcap idea I turned into a side project, and had an enormous amount of fun with.
What I didn’t expect was to encounter an extremely interesting performance optimisation puzzle as the centrepiece of my second (v1.1) release.
Now, the app is firing on all cylinders:
2FA codes snap into existence as soon as you launch.
The algorithms for finding interesting codes are much faster.
Our powerful multi-core CPU is fully utilised with parallel computation.
Download Check ’em: The Based 2FA App today!