
The Magic of Sets
Speed up your app by 98% with a swish and a flick

Mobile devs get a bad rap when it comes to data structures & algorithms.
Unless you’re talking about animation jitters, complex optimisation problems rarely filter down to us on the client-side.
With ARM chips chugging along like a Firebolt at 2 teraflops, and when we’re dealing with a few dozen paged elements on-screen at once, the difference between O(n) and O(log(n)) rarely matters to us.
The Set is like the Rupert Grint of data structures. Less star power than the Array (Daniel Radcliffe); and less sheer brilliance than the Dictionary (Emma Watson); but really unmatched in owning the role it’s given.
To help you build up your intuition for when to use this red tetrahedral peg, I’ll talk you through some real-world scenarios when I encountered triangular holes.
Improving the UX of API polling with partial results
Recently, I was working on a feature that involved a long-running job on our backend. A user would sign up, and it might take us 10 minutes to process all the data we needed to show them.
While we were processing, we wanted to give the user some feedback, so we settled on a polling system where every 10 seconds, we returned partial results to the user.
The API we had used pagination, so the first-page results displayed after the first 10 seconds could be completely different list to the results after 1 minute or longer.
To ensure the experience wasn’t confusing, we need to:
combine partial results with existing results
remove duplicate items
maintain the ordering
Removing duplicates
Casting an Array of values into a Set instantly casts a vanishing spell on those pesky duplicates. Simply cast the incantation Array(Set(data)) to transfigure the result back into an Array.

Since Sets are unordered, you can’t guarantee the order of the resulting Array will be the same as you started with - conform your data type to Comparable and sort it to keep the ordering right.
How can I XOR my custom data structures?
I used to think Set algebra was as fun as a date with Umbridge, but I didn’t truly appreciate the power I was playing with.
symmetricDifference is a property unique to Sets which allows you to rapidly find out which items exist in one Set, but do not exist in another Set.
In a Venn diagram, it’s everything in circle A that does not overlap with B - equivalent to a XOR operation. Because I’m terrified of getting sent to Azkaban for copyright violation, here is a diagram I drew myself in MS Paint:

Purging the keychain on logout
In your app, you might be storing some important pieces of data on the iOS keychain.
Some of this data is important to keep on-device between login sessions (e.g. a unique download token to track a device in analytics). Most, however, should be erased if a user logs out (e.g. auth tokens or your user’s email address).
We could maintain a list of keychain items to specifically remove on log-out, but in a complex app you might have 50+ items in the keychain. More likely, the list of items to keep is far smaller.
Rather than maintaining a long list of items to purge on logout, we can use symmetricDifference to maintain a much smaller list of items to persist on logout, and purge everything else

symmetricDifference, an operation someone on Twitter once didn’t believe me when I said I’d used Why is this algorithm taking 10 minutes?
Checking whether a value exists in an Array is like looking for an invisibility-cloaked Horcrux in a haystack - you’ll pretty much need to feel every bit of grass to have a hope of detecting it. When using a Set, it’s like casting Revelio and instantly detecting that pesky evil soul fragment.
Efficient membership checks are truly the star of the show with Sets - working out whether a given item is a member of the set is, on average, an O(1) operation, compared to O(n) in an Array.
Advanced aside: Why is membership lookup so fast in Sets?
Sets are usually implemented via hash table, which enables them to grant the O(1) time complexity for insertion, deletion, and membership checks.
Each element in the Set is stored as a key in the hash table, with the corresponding value for each key left as `null`.
Hash functions provide a direct mapping between the key (i.e. the hashed value of the Set item) and its physical location in memory, meaning you just need to compute the hash and look directly at that location in memory to see if the member of the Set exists.
Conversely, an Array is a contiguous block of data stored in memory, so you must traverse every individual element to find out whether something exists - and in the worst case - when the element doesn’t exist - it has to traverse every single element to be sure!
Your phone is rarely dealing with many items at once, and so this difference can often go unnoticed. But when you’re dealing with a ton of items; that can seriously matter.
Speeding up operations by 98%
I once worked on a system which downloaded up to 1,000,000 items at once to a user’s mobile phone, and stored this data locally. The user could browse this data and choose to upload parts of it to our backend.
To prevent uploading duplicate data (and wasting considerable amounts of battery and data), the backend gave us a list of already-uploaded IDs for each data item, so we can simply upload the difference.
We checked whether each item of fresh data was in this list of uploaded IDs, and flagged them before storing them in Core Data. This meant that the user could browse this data without needing to upload it a second time.
The original implementation took these IDs as an array, and could take up to 10 minutes just to flag these previously uploaded items if a lot of data existed - a classic O(n^2) operation since we’re checking every downloaded ID against every previously uploaded ID.
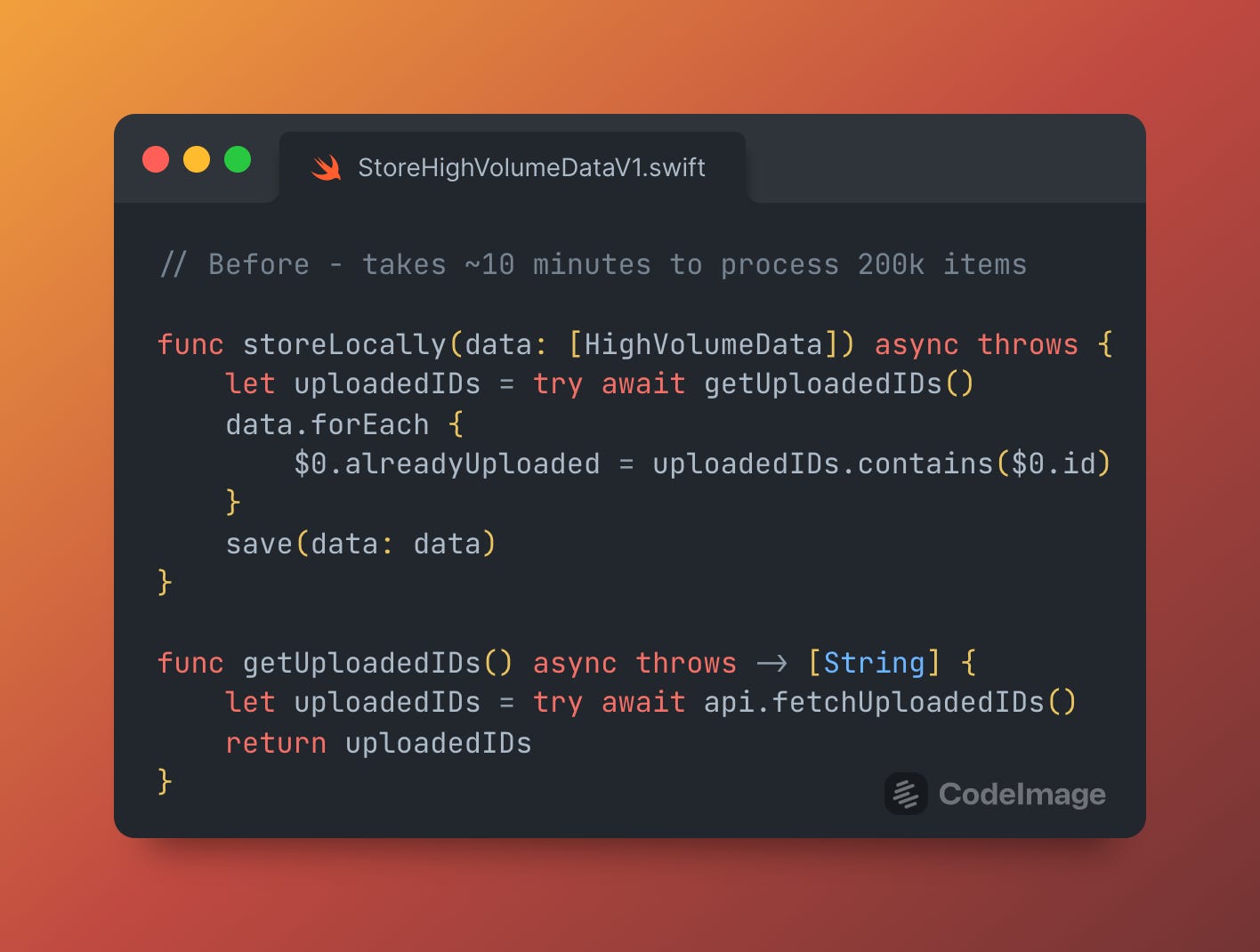
Switching to a Set ran this whole operation faster than you could say “Quidditch” - 12 seconds to be exact. By multiplying the O(1) operation of Set membership checks by the number of items to check, n, we convert the total process into O(n).

Now you’re mastering the wizardry of data structures!

Your new secret weapon
Sets provide a powerful and efficient way to tackle many everyday engineering tasks. Embracing Set operations can lead to significant improvements in user experience and processing times, and prove to your comrades on the backend that you know your stuff when it comes to having fun with data structures.